Publications
(* indicates equal contribution)
Mitigating Object and Action Hallucinations in Multimodal LLMs via Self-Augmented Contrastive Alignment
TD;LR: This paper proposes SANTA, a post-training scheme that first exposes the model’s hallucination tendency via negative construction, and then uses contrastive learning to align extracted visual-tracklet features with language-phrase features.
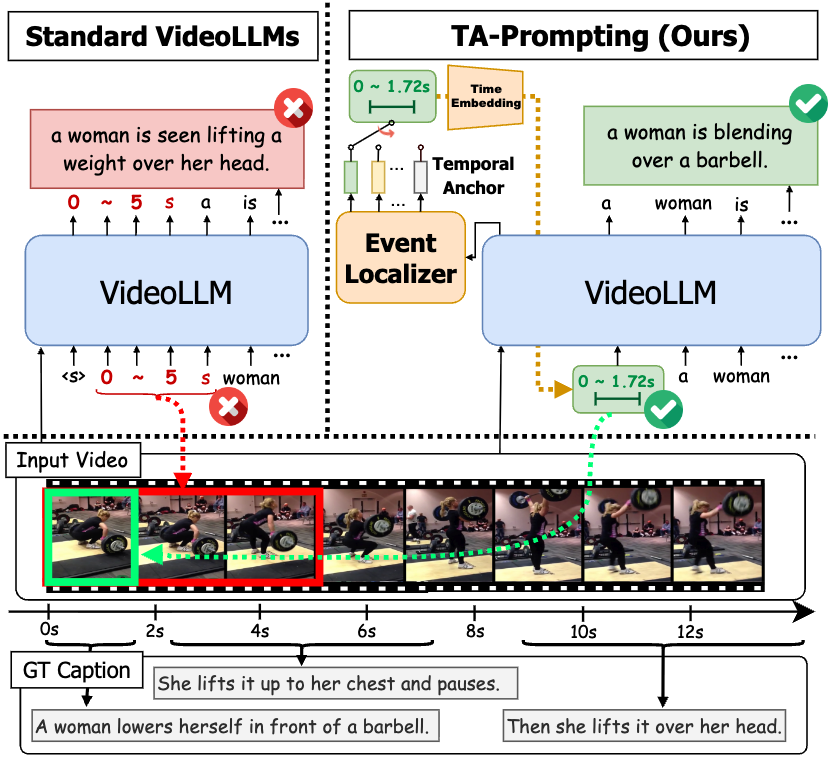
TA-Prompting: Enhancing Video Large Language Models for Dense Video Captioning via Temporal Anchors
TD;LR: This paper proposes TA-Prompting, a two-stage Video-LLM post-training scheme that uses proposed temporal anchors to improve event localization and dense video captioning.

EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction
TD;LR: This paper proposes EMLoC, an emulator-based LoRA fine-tuning method that lets users train large models with the same memory cost as inference (e.g., training a 38B model only requires 24G GPU).

Videomage: Multi-subject and motion customization of text-to-video diffusion models
TD;LR: This paper introduces Videomage, the first framework to enable multi-subject and motion customization of text-to-video diffusion models.
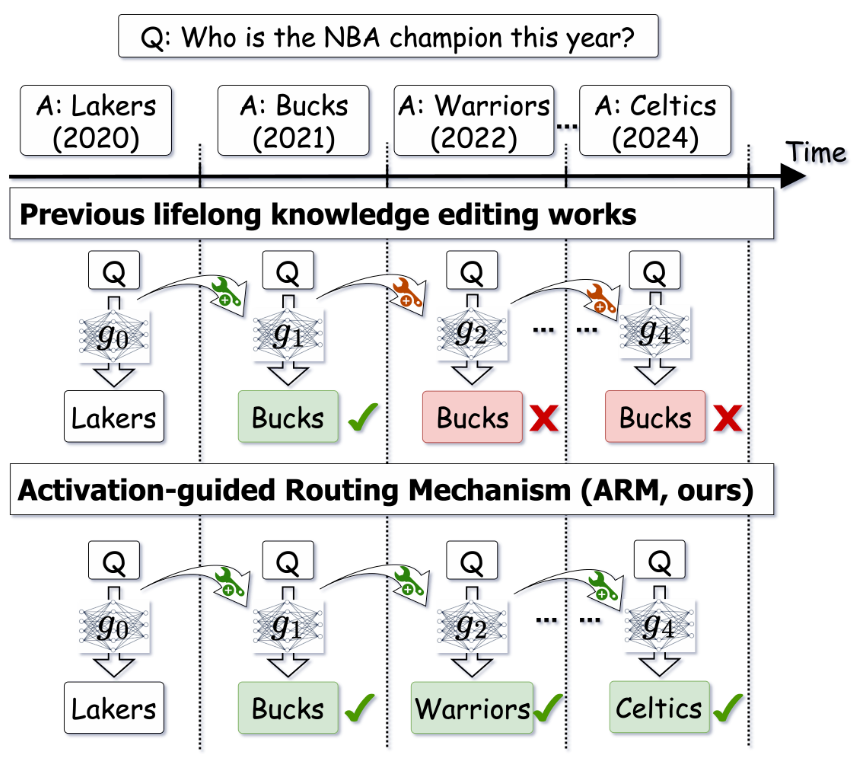
Serial Lifelong Editing via Mixture of Knowledge Experts
TD;LR: This paper proposes a Mixture-of-Knowledge-Experts framework with an activation-guided routing mechanism for serial lifelong knowledge editing in LLMs.
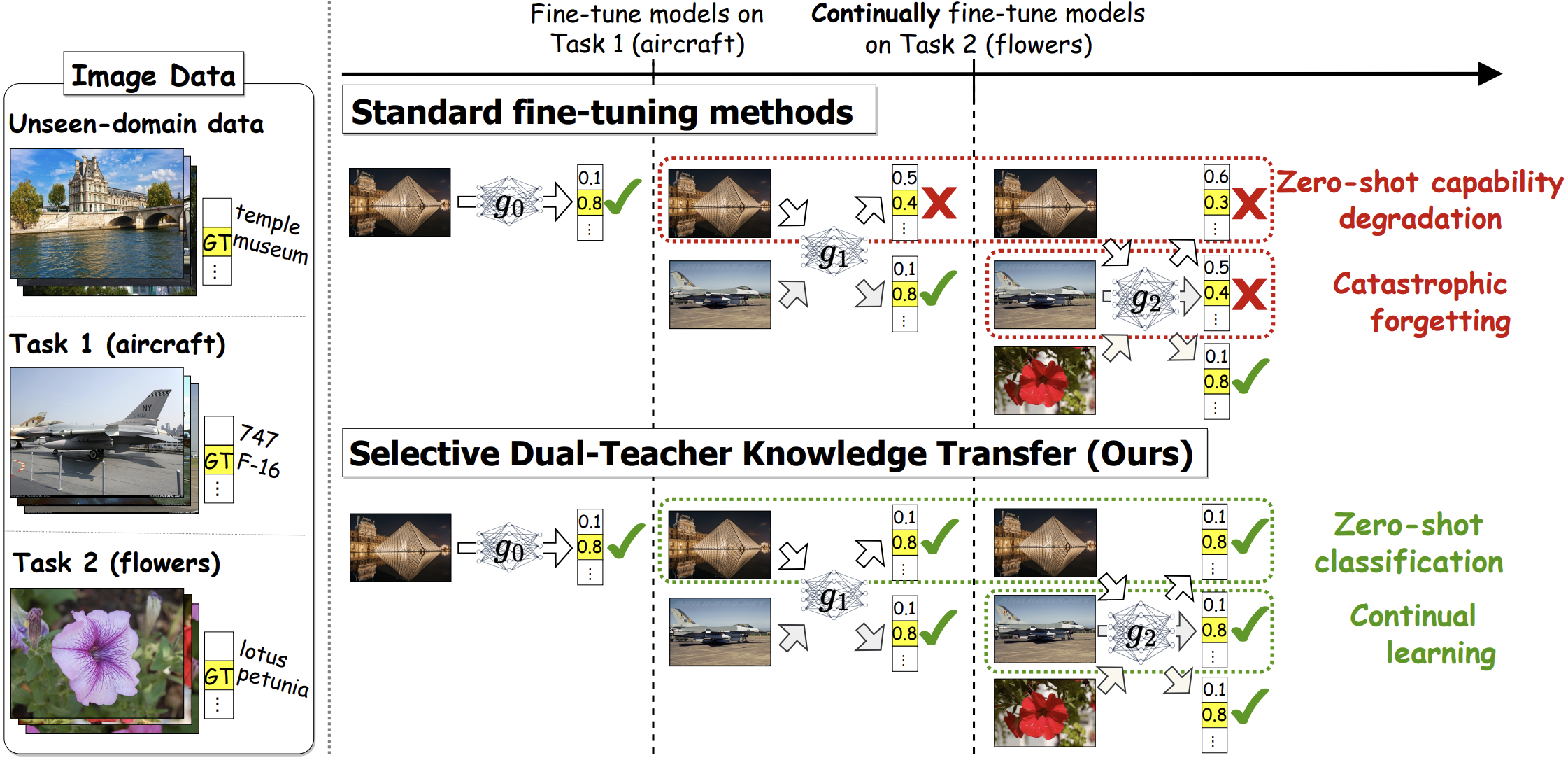
Select and Distill: Selective Dual-Teacher Knowledge Transfer for Continual Learning on Vision-Language Models
TD;LR: This paper proposes Select-and-Distill, a dual-teacher distillation method that preserves zero-shot ability while reducing forgetting in continual VLM learning.

Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers
TD;LR: This paper introduces Receler for erasing concepts from pre-trained diffusion models, exhibiting sufficient locality (i.e., w/o affecting non-target concepts) and robustness (i.e., against paraphrased and adversarial attacks) properties.
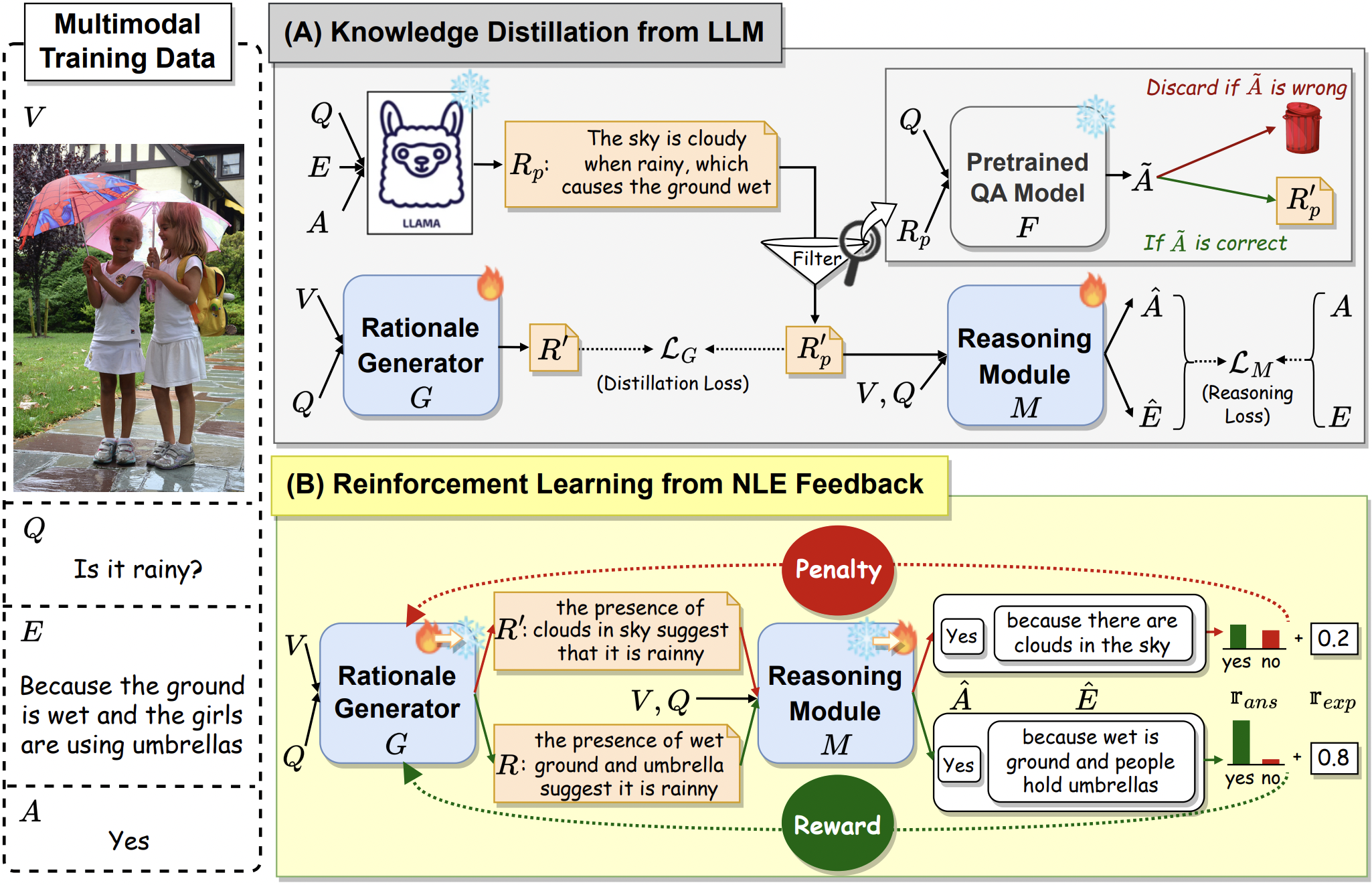
RAPPER: Reinforced Rationale-Prompted Paradigm for Natural Language Explanation in Visual Question Answering
TD;LR: This paper introduces Rapper, RAPPER, a two-stage training paradigm, for VLM to mitigate implausibility and hallucination issues in generating natural language explanations (NLEs) through reinforced language-based feedback.